“Roll-and-keep” is a concept popularized by the Legend of the Five Rings RPG. From 1st to 4th Edition, L5R used the following system: the player rolls a pool of (exploding) d10s, keeping a number of the highest dice rolled. This is thus a generalization of keep-highest dice pools (= keep one) and success-counting dice pools (= keep all).
A similar concept can be applied to many schemes that have been proposed for D&D-style character generation. For example, roll 5d6, keeping the highest three dice; and/or rolling seven ability scores, keeping the highest six.
However, computing the probabilities for this type of dice pool is not as easy as it is for keep-highest or success-counting. In this article, we’ll look at systems where the player rolls a homogeneous pool of 


Existing calculators
Popular existing dice probability calculators are not capable of efficiently computing the probabilities for this type of system in closed form. By “closed form” I mean “not Monte Carlo” ; while Monte Carlo methods are very flexible, they can take a long time to converge, especially compared to the precision of a direct calculation.
Here are some examples:
AnyDice
AnyDice appears to take exponential time in
output [highest 5 of 10d[explode d10]]times out. (n.b. At default, AnyDice explodes dice up to two times, not counting the base roll. In this example, the maximum outcome on each die is 
output [highest 8 of 16d10]times out as well, as does
output [highest 2 of 20d10]Troll
The conference paper for the Troll dice roller and probability calculator says:
For example, the game “Legend of Five Rings” [18] uses a roll mechanism that can be described in Troll as
sum (largest M N#(sum accumulate x := d10 until x<10))where M and N depend on the situation. With M = 3, N = 5 and the maximum number of iterations for accumulate set to 5, Troll takes nearly 500 seconds to calculate the result, and it gets much worse if any of the numbers increase.
To be fair, this paper was presented more than a decade ago, and hardware has advanced considerably since then. cpubenchmark.net shows a factor of about 5× in single-threaded performance and 33× in overall performance from the CPU used in the paper to my current desktop CPU. However, 500 seconds is a long time, and even this advancement in hardware is not nearly enough to overcome even modest increases in the number of dice due to the exponential time of the algorithm.
Troll does do better than AnyDice on the last of the three.
SnakeEyes
A Lua-language calculator that runs locally in the browser. (Hence why I don’t feel bad linking a futile L5R script in this case, as it’s not putting load on someone else’s server. I don’t recommend clicking on that if your computer is prone to hanging though.) Unfortunately, this too cannot complete the first two calculations in a reasonable amount of time, though it also does better than AnyDice on the third. The author also did come up with an optimized script for L5R in particular.
I believe the difference is that AnyDice enumerates all 

lynks.se
There does exist a website with L5R probabilities: lynks.se. However, if you look at that webpage’s source code, you’ll see that the probabilities have been precomputed and stored in static arrays. Furthermore, there is a small but noticeable amount of noise in the data, indicating that it was computed via Monte Carlo rather than a closed-form method.
pyPBE
Another Monte Carlo application, this time for D&D-style character generation. Web version.
I don’t mean this as harsh criticism of any of these resources. They are very accessible and are a great service to the RPG community. It also may not be simple to integrate semi-specialized algorithms into a generalist online dice calculator.
But, like the archetypical adventurer, we always want more.
Convolution
How can we compute these probabilities more efficiently? Let’s look at a simpler problem first: finding the probability mass function (PMF; “Normal” data on AnyDice) of a sum of dice without dropping any of them.
The brute-force method is to enumerate all 
A much faster method to to do the addition via iterated convolutions. Instead of the brute force method, we could iteratively take the PMF of the first 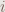




which is nicely polynomial compared to the exponential time of the brute-force algorithm.1
Unfortunately, the roll-and-keep system makes things more difficult. If we keep only the PMF of the sum from iteration to iteration, we have no way of correctly dropping the new lowest die as we consider each die in turn. On the other hand, if we track the probability distribution of all 


Cutting up the probability space
Instead, what we’re going to do is cut up the probability space into a polynomial number of disjoint pieces, where the probability of landing in each is the product of a number of factors which we can compute using iterated convolutions just like the sum of dice above. We’re going to parameterize the pieces using the following parameters:
- The lowest single roll
among the kept dice.
- The number of kept dice
that rolled strictly greater than
- The sum
of those
dice.
The total result of each piece is then 
The probability of landing in one of these pieces is equal to the product of the following:
- The lo factor: The probability that, out of
dice that were less than or equal to the lowest kept die, all of them will roll
of them roll exactly equal to
- The sum factor: The probability that, out of
- The binomial factor: The number of ways of assigning
The lo factor
To compute the chance that at least 



Consider each vector corresponding to 

![\left[ P_<\left( \ell \right), P_=\left( \ell \right) \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+P_%3C%5Cleft%28+%5Cell+%5Cright%29%2C++P_%3D%5Cleft%28+%5Cell+%5Cright%29++%5Cright%5D&bg=e9e7e3&fg=6a524a&s=0&c=20201002)



Here’s a pictorial representation for 
| ⚂ × 0 | ⚂ × 1 | ⚂ × 2 | ⚂ × 3 | |
| 1 die | ⚀, ⚁ = 2/6 | ⚂ = 1/6 | ||
| 2 dice | ⚀⚀, ⚀⚁, ⚁⚀, ⚁⚁ = 4/36 | ⚀⚂, ⚁⚂, ⚂⚀, ⚂⚁ = 4/36 | ⚂⚂ = 1/36 | |
| 3 dice | ⚀⚀⚀, ⚀⚀⚁, ⚀⚁⚀, ⚀⚁⚁, ⚁⚀⚀, ⚁⚀⚁, ⚁⚁⚀, ⚁⚁⚁ = 8/216 | ⚀⚀⚂, ⚀⚁⚂, ⚀⚂⚀, ⚀⚂⚁, ⚁⚀⚂, ⚁⚁⚂, ⚁⚂⚀, ⚁⚂⚁, ⚂⚀⚀, ⚂⚀⚁, ⚂⚁⚀, ⚂⚁⚁ = 12/216 | ⚀⚂⚂, ⚁⚂⚂, ⚂⚀⚂, ⚂⚁⚂, ⚂⚂⚀, ⚂⚂⚁ = 6/216 | ⚂⚂⚂ = 1/216 |
Each row/vector is the convolution of the previous vector and the first vector. Note how instead of counting all the individual possibilities that fall into each cell, we can convolve the previous vector and the first vector.
The sum factor
Again, we’ll compute an array, this time indexed by 







The binomial factor
This is just the binomial coefficient 

The outer loop
Now we just have to loop, multiply, and accumulate the three factors over all values of 

On my desktop (Intel i5-8400), my NumPy-based implementation can compute the PMF of any of the examples above in under 5 milliseconds.
Similar strategies can be used to compute the PMF of:
- The sum of the lowest
- The
- The sum of the
th to the
th lowest dice, i.e. dropping dice from both the top and the bottom, with the binomial factor becoming a multinomial factor. Though this is getting sketchy from both a computational and from a game design perspective.
Source code
GitHub. At time of writing the API is far from stable, so I wouldn’t advise building anything serious around this just yet.
1 It’s possible to do even better asymptotically using a fast Fourier transform. However, according to scipy this is estimated to only be faster than the quadratic direct algorithm past about a range of 500, which is greater than pretty much any tabletop RPG will make use of. There’s also the option of doing binary splits but a) this only improves the time by a constant factor, and b) our final algorithm needs the intermediate PMFs anyways.
It is conceivable will lose less to floating-point precision, but I haven’t worked this out yet.
